Google's TurboQuant: The AI Memory Compression Breakthrough the Internet Is Already Calling 'Pied Piper':
When Google Research unveiled TurboQuant on Tuesday, the internet didn't waste a second.
Introduction: Beyond a Speed Upgrade -- A Fundamental Rethink of AI Memory:
When most people hear about a new AI efficiency breakthrough, they imagine incremental gains -- a slightly faster response time, a marginally lower server bill. But what Google Research announced this week is something far more consequential. TurboQuant, the new ultra-efficient AI memory compression algorithm unveiled on Tuesday, isn't an incremental improvement. According to early expert reaction, it may be a paradigm shift in how AI systems store and access working memory.
The comparison the internet landed on almost immediately was not to a rival tech company or a competing research lab. It was to a fictional startup from a television show -- and that tells you everything about the scale of excitement this announcement has generated. Within hours of the announcement, developers, researchers, and industry commentators were drawing the same inevitable parallel: Pied Piper, the fictional compression startup at the heart of HBO's cult classic series Silicon Valley, which ran from 2014 to 2019. The joke, as anyone who watched the show will recognise, is almost too on-the-nose to be accidental.
The Pied Piper Connection: Why the Internet Can't Stop Making This Comparison:
The show followed the founders of Pied Piper as they navigated the brutal realities of Silicon Valley -- facing competition from larger companies, catastrophic fundraising rounds, relentless product challenges, and the occasional unlikely triumph, including a memorable appearance at a fictional version of TechCrunch Disrupt.
Pied Piper's breakthrough technology on the show was a lossless compression algorithm that shrank file sizes to a degree that defied conventional wisdom -- extreme compression without any meaningful loss in quality.
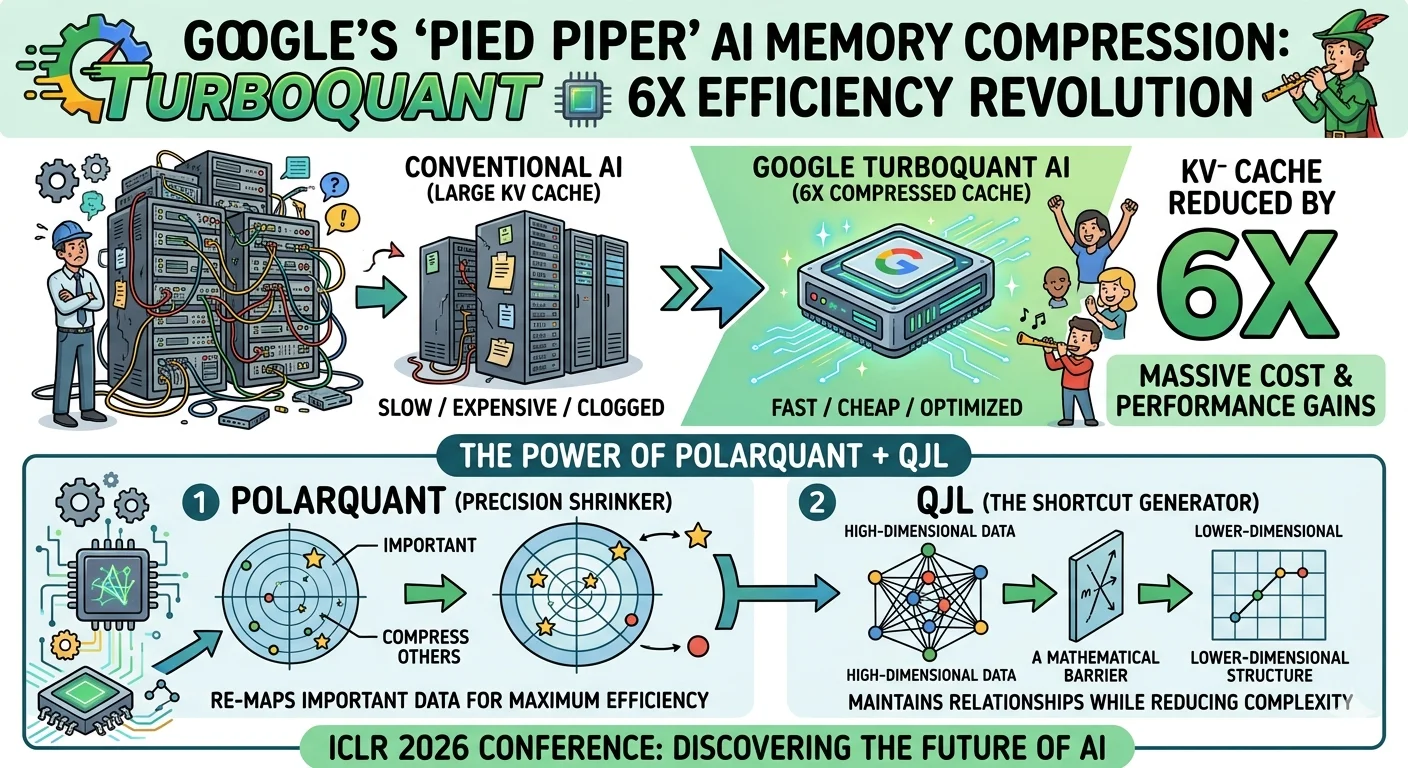
Google Research's TurboQuant follows the same core principle, but applied to one of the most costly bottlenecks in modern AI: the KV cache, the runtime working memory that large language models rely on during inference. Same fundamental idea. Different domain. And the internet noticed within hours.
What Is TurboQuant: Google's New AI Compression Algorithm Explained:
Google Research has described TurboQuant as a novel method for shrinking AI's working memory without impacting performance -- a claim that, if it holds up to peer scrutiny, would have sweeping implications for the economics of AI deployment.
The compression method works by applying vector quantization to the KV cache -- the system AI models use to store intermediate data while processing and generating output. By compressing this cache, TurboQuant allows AI systems to hold more information in less space, reducing the computational resources required during inference while maintaining accuracy. Two core innovations sit at the heart of the technology.
Google Research plans to present their full findings at ICLR 2026 next month, where they will detail the two methods making TurboQuant possible: PolarQuant, the quantization technique, and QJL, a training and optimization method that makes the compression viable at scale. Understanding the underlying mathematics is the domain of researchers and computer scientists -- but the results are generating excitement well beyond academic circles.
Why This Matters: The Real-World Impact of a 6x KV Cache Reduction:
A compression ratio of at least 6x in AI working memory is not a minor technical footnote. For organisations running large language models at scale, the KV cache is one of the primary drivers of infrastructure cost -- consuming enormous GPU memory and limiting how much context a model can process at any given time.
Reducing that memory footprint by six times or more would mean AI systems could process significantly longer contexts, serve far more concurrent users, and do so at a fraction of today's infrastructure cost. For enterprises deploying AI across customer service, healthcare, legal, or financial applications, that is not a performance upgrade -- it is a fundamental shift in what is economically viable.
The implications extend beyond cost. Longer context windows enabled by efficient KV cache management could unlock AI capabilities that are currently impractical -- more coherent long-form reasoning, better document comprehension, and more accurate multi-step decision-making.
Google's DeepSeek Moment: What Industry Leaders Are Saying:
The reaction from the broader technology industry has gone well beyond Pied Piper jokes. Cloudflare CEO Matthew Prince drew a comparison that carries significant weight in the current AI landscape: he called TurboQuant Google's DeepSeek moment.

The Hidden AI War
Nobody Is Telling You About
Our latest documentary deep-dive into the geopolitical struggle for machine intelligence dominance. Explore the two paths of AI development: open source vs. closed architecture.
That framing is a direct reference to the efficiency gains delivered by the Chinese AI model DeepSeek -- which stunned the global AI industry earlier this year by achieving competitive performance at a fraction of the training cost of its rivals, even on inferior hardware. DeepSeek forced a global rethink of AI training economics. TurboQuant, Prince and others suggest, could do the same for AI inference.
For life sciences, finance, and enterprise technology sectors currently weighing major AI infrastructure investments, the timing of this announcement could not be more significant. If TurboQuant's efficiency gains translate into real-world deployment at the scale Google Research suggests, the cost-benefit calculations underpinning many of those investment decisions may shift considerably.
Key Takeaways: TurboQuant's Potential Impact at a Glance:
Here is a summary of the key TurboQuant developments covered in this article:
-
TurboQuant: Google Research's new AI memory compression algorithm, designed to shrink the KV cache by at least 6x without sacrificing model performance or accuracy.
-
Vector quantization: The core technical method underpinning TurboQuant's compression approach, applied directly to AI working memory during inference.
-
PolarQuant: The quantization technique that forms one half of TurboQuant's technical foundation, to be presented at ICLR 2026.
-
QJL: The training and optimization method that makes TurboQuant's compression viable at scale, also to be presented at ICLR 2026.
-
KV cache: The runtime working memory bottleneck in large language models that TurboQuant directly targets -- and whose compression drives the algorithm's efficiency gains.
-
The Pied Piper parallel: The fictional Silicon Valley startup whose lossless compression breakthrough mirrors TurboQuant's real-world ambitions closely enough to become an instant internet meme.
-
Google's DeepSeek moment: The framing used by Cloudflare CEO Matthew Prince, positioning TurboQuant as a potential inflection point in AI inference efficiency comparable to DeepSeek's impact on training economics.
Conclusion: A Quantum Leap in AI Efficiency -- If the Research Delivers:
TurboQuant is not yet a deployed product -- it is a research breakthrough scheduled for peer review at one of the world's leading AI conferences next month. But the excitement it has generated, from developer communities to C-suite technology leaders, reflects something genuine: the AI industry has been waiting for a meaningful answer to the inference cost problem, and Google Research may have just offered one.
The experts and industry observers reacting to this announcement are largely aligned: if TurboQuant's claimed 6x KV cache compression holds up under rigorous scrutiny and translates into real-world deployment, it represents not just a performance gain but a fundamental reimagining of AI infrastructure economics. The questions that have driven up cloud bills and constrained AI ambitions -- how do we store more context with less memory?
How do we serve more users without doubling hardware spend? -- may soon have a compelling answer.
For AI developers, enterprise technology leaders, and infrastructure investors, the message is straightforward: watch ICLR 2026 closely.
If TurboQuant delivers on its promise, the organisations that move fastest to understand and adopt this technology will be best positioned to lead the next wave of efficient, scalable AI deployment.






